



KNN及影响其算法性能的优化(交叉验证、是否过拟合等)——自学第二篇
编辑:佚名 日期:2024-03-12 13:24 / 人气:
- 介绍实现KNN的两种基础算法
- 通过使用交叉验证、防止过拟合、超参数调整等方法对KNN的计算精度进行调整。
- 总结KNN算法和机器学习流程
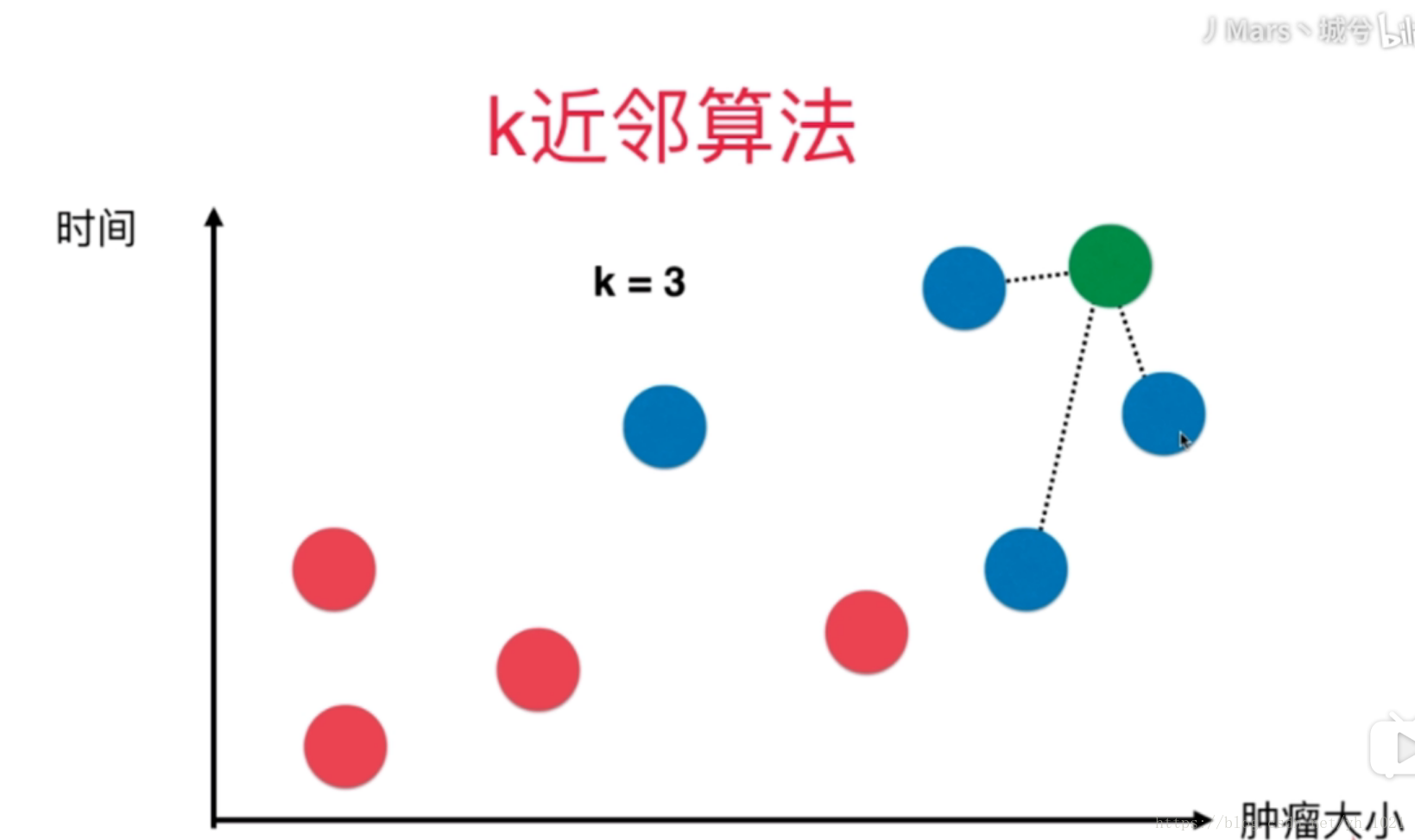
如图所示为每一个病人的肿瘤大小与其发现肿瘤的时间的关系,以此来判断肿瘤是否为恶性,其中恶性为蓝色,良性为红色,如果新来的病人为绿色的,需要用knn判断是否为恶性。
若k值取3,则找出之前数据中的点离新的数据点的距离最近的三个点,再分别将这三个点进行投票,若三个点中蓝色的居多,则新的点也为蓝色(恶性),反之则为红色(良性)。
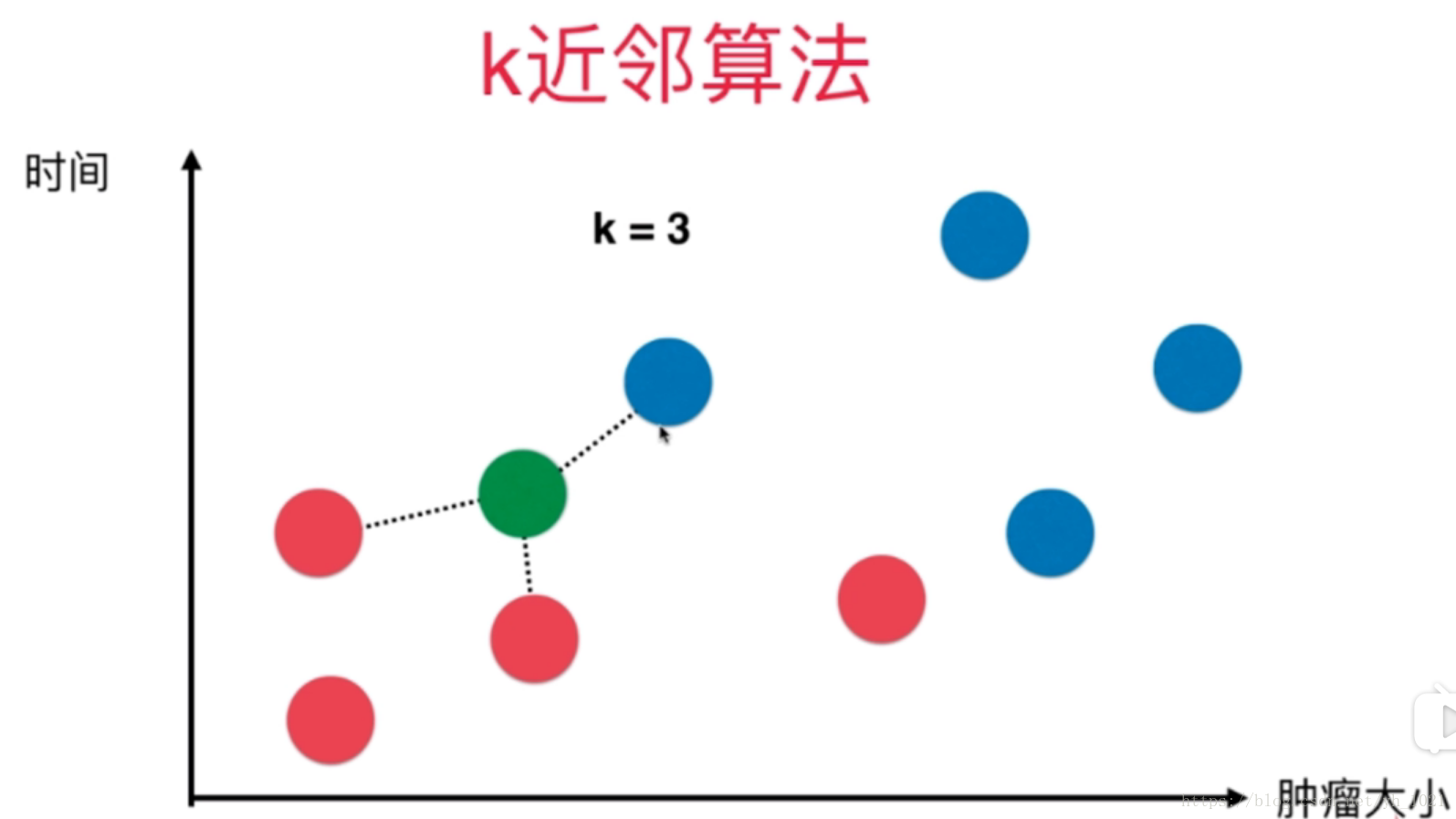
上图所示离绿色点最近的三个点中,有两个为红色一个为蓝色,所以最终绿色的点属于红色(良性)。
新的数据属于离它最近的k个数据中数量最多的类别
距离通过计算两个点(a和b)的欧拉距离得到:
注:其中i为某一个点的第i个维度上的坐标
整体代码如下:
方法一:底层算法
方法二:利用skleran库
采用scikit-learn中已经封装好的knn库
scikit-learn中训练模型的步骤
- 加载机器学习模块
- 创建算法实例(将算法的类实例化)并传入参数
- 拟合训练数据集,训练模型
- 用predict预测数据
问题:如果用所有的数据集都输入模型得到的模型很差并且没有其他的数据对其进行调整,那遇到新的数据时的预测效果会不好。(用所有的数据都作为训练集是不恰当的)
解决:
- 分训练集和测试集:训练集和测试集为7:3,用训练数据训练模型,再用测试集检验模型好坏
- 交叉验证
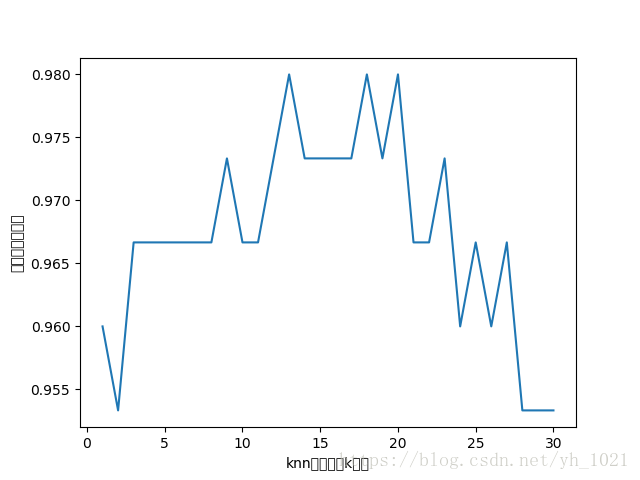
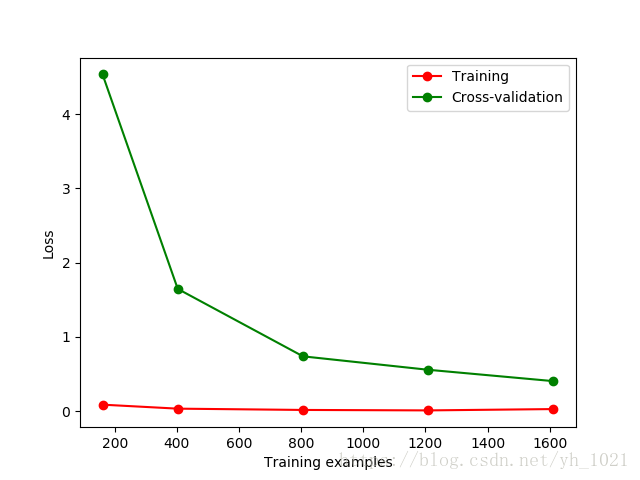
可视化不同k值的精度和误差,并判断是否过拟合
不同k值的精度值折线图
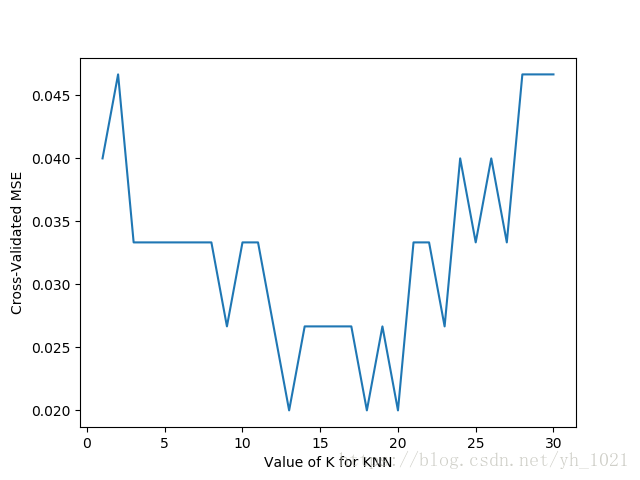
用平均方差来计算不同k值的误差曲线
通过学习曲线模块看是否产生过拟合
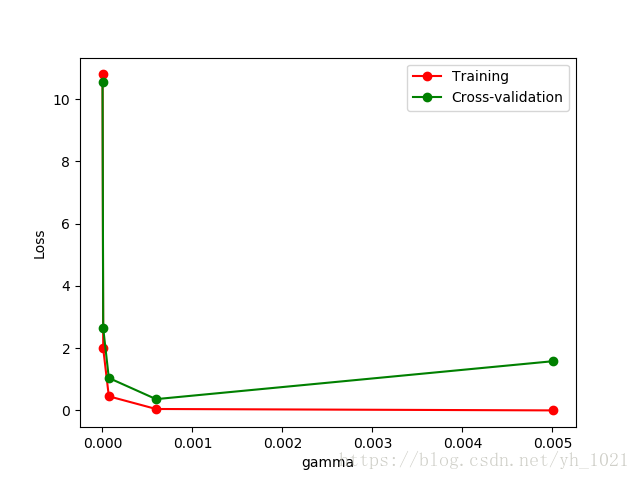
用验证曲线 validation curve 选择超参数gamma,找到正常拟合的参数,防止过拟合和欠拟合,如图可知选择gamma=0.001时未发生过拟合。
- 超参数:在算法运行前需要决定的参数
- 模型参数:算法过程中学习的参数
(1)超参数——K
上面已经讨论过不同的k值对模型的精确度的影响,可以通过遍历k值得到精确度的折线图
(2)超参数——距离权重
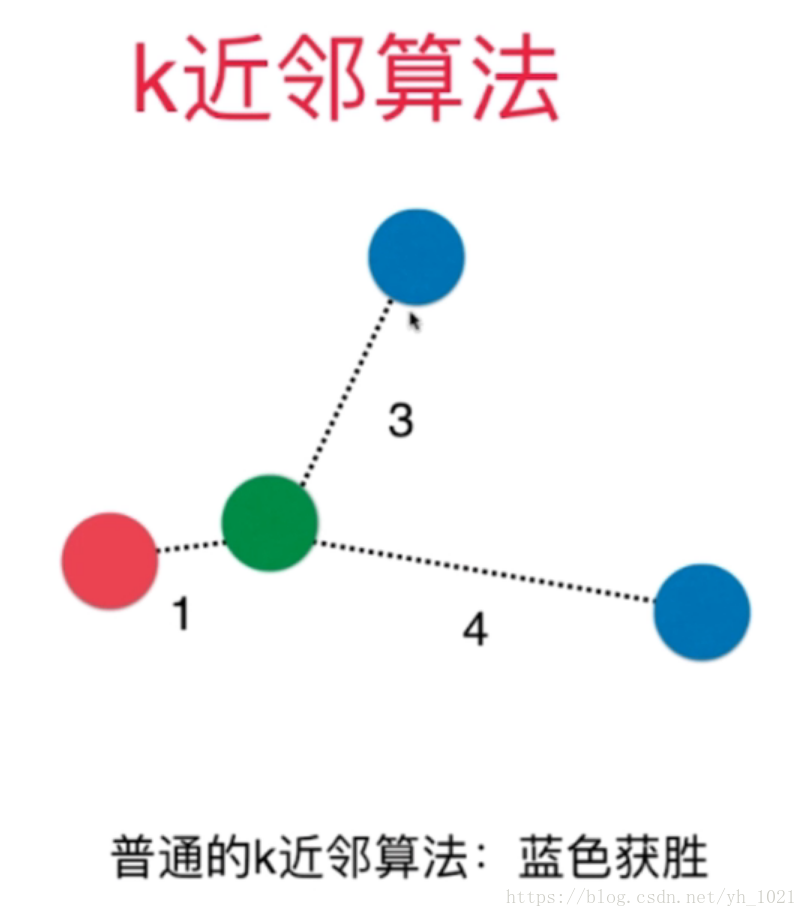
在KNN中K的值为超参数,当然除此以外还有很多超参数。比如下图所示的KNN算法中,若只考虑离绿色的点最近的三个点中哪一类的数量最多,那么绿色的点将属于蓝色。
但是很明显绿色的点离红色的更近,所以在使用KNN算法中还需要将距离的权重考虑在内。将距离的倒数作为权重,距离越远,权重越小。
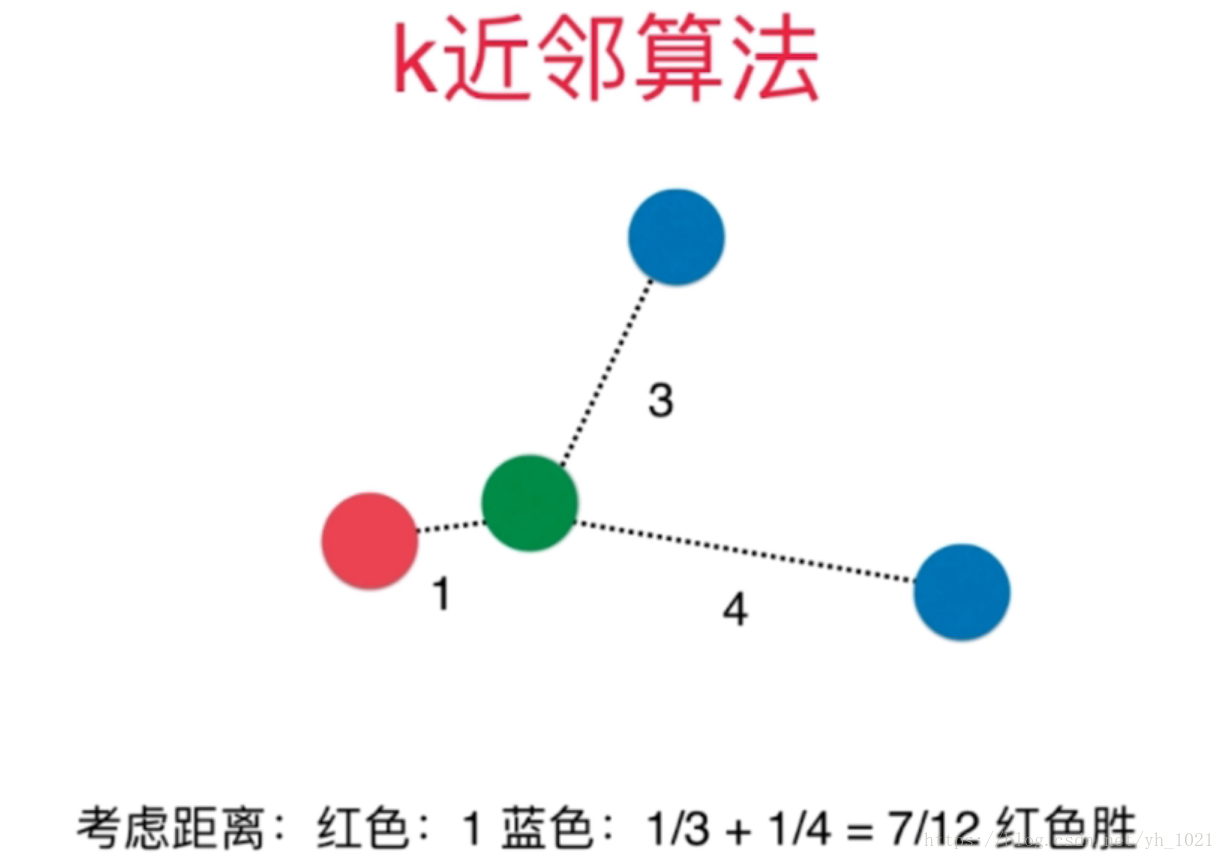
考虑了距离权重之后能够很好的解决平票问题,若K=3时,距离绿色点最近的三个点分别为三个不同的分类,则需要根据权重的大小选择最优解。
(3)超参数——P
明科夫斯基距离:
若P等于1,该式子为曼哈顿距离,当P=2为欧拉距离
(可设置不同的P值,得到精确度最高的P)
总结:可使用搜索的策略,遍历各项超参数,得到精确度最高的一组超参数
概念:Grid Search:一种调参手段,是一种穷举搜索:在所有候选的参数选择中,通过循环遍历,尝试每一种可能性,表现最好的参数就是最终的结果。其原理就像是在数组里找最大值。(为什么叫网格搜索?以有两个参数的模型为例,参数a有3种可能,参数b有4种可能,把所有可能性列出来,可以表示成一个3*4的表格,其中每个cell就是一个网格,循环过程就像是在每个网格里遍历、搜索,所以叫grid search)
作者:七八音
链接:https://www.jianshu.com/p/55b9f2ea283b
來源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。
将网格搜索和交叉验证相结合能得到更好的模型,sklearn中有这样的类GridSearchCV将两者相结合,这个类实现了fit,predict,score等方法,被当做了一个estimator,使用fit方法可得到最佳参数
输出:
注:因为时穷举搜索,耗时比较长,先定大范围再细化
- 解决多分类问题
- 思想简单,功能强大
- 可以解决回归问题
解决回归问题:
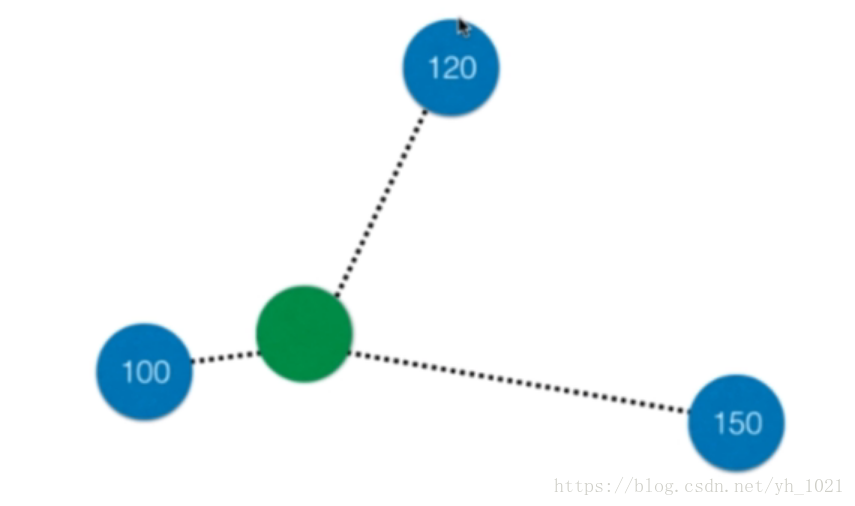
离绿色点最近的有三个蓝色点,可以将距离作为权值,求出三个点的加权平均作为绿色点的值,也可直接将三个点的平均值作为绿色点的值,从而进行值的预测。
缺点:
- 效率低下,计算量大
- 与数据高度相关,若3个近邻中有两个误差大的数据,则会有很大影响
- 预测结果不具有可解释性,只能知道某个数据属于某一类,但无法知道为什么
- 如果数据维数较多,会发生维数灾难,随着维度增加,“看似相近”的两个点的
距离会越来越大(10000维的距离就为100)
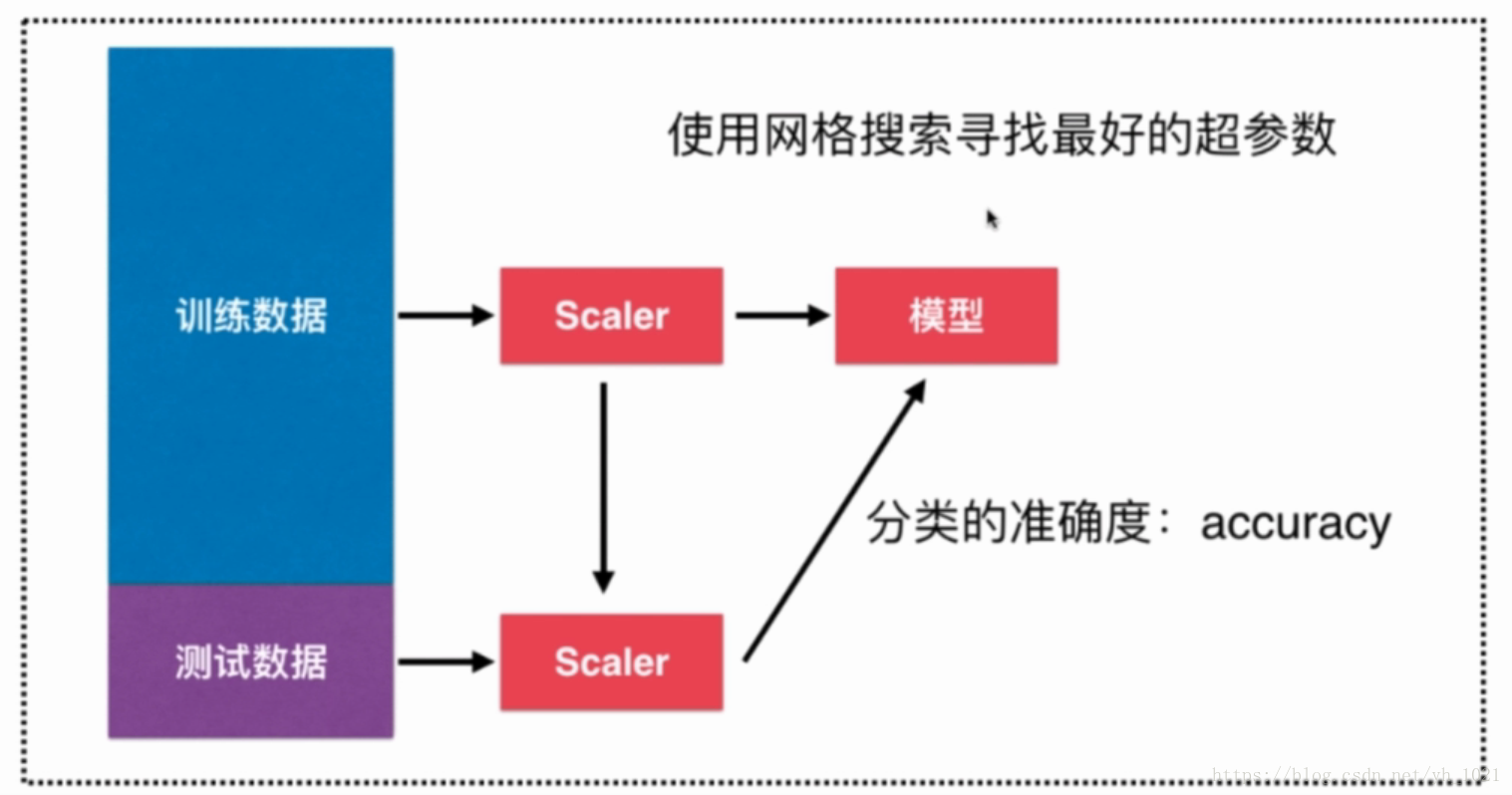
Scaler为归一化
内容搜索 Related Stories
推荐内容 Recommended
- 一文解读房改房和商品房有什么区别?04-22
- 直播间下单,外卖送到家,抖音还藏了这一手04-22
- 光伏系统的性能优化:回顾,Archives of Computational Methods in 04-22
- 本科想出国留学,应该从什么时候开始准备最好04-15
- 优化原理04-15

